本文是对 R 中精算学专用包 actuar 使用的一个简单教程。actuar 项目开始于 2005 年,在 2006 年 2 月首次提供公开下载,其目的就是将一些常用的精算函数引入 R 系统。目前,提供的函数主要涉及风险理论,损失分布和信度理论。
如题所示,本文是我在学习 actuar 包过程中的学习笔记,主要涉及这个包中一些函数的使用方法和细节,对一些方法的结论也有稍许探讨,因此能简略的地方简略,而讨论的地方可能讲的会比较详细。闲话少提,下面正式开始学习!
1、数据分组
分组数据是精算学中常用的数据格式,比如我们要把不同风险类别的人群进行分别统计。假设我们要把一组连续变量分为 n 组,显然需 n+1 个边界。
函数
gouped.data(Group = c(...), freq1 = c(...), freq2 = c(...),
..., right = TRUE, row.names = NULL)
使用注意:
1) Group 是分组的临界值,freq1 和 freq2 是对应组别的频数。Group,freq1 和 freq2 可以随意命名,但是一定要把临界值向量放在第一个位置。
2) Group 向量要比 freq 向量多出一个长度。
3) 默认分组区间是左开右闭,如果想变为左闭右开可以设置 right=FALSE。row.names 可以自定义行的名称。
4) 返回的是一个数据框。特别要注意对第一列的处理。
> x=grouped.data(Group= c(0, 25, 50, 100, 150,250, 500),
Line.1 = c(30, 31, 57, 42, 65, 84),
Line.2 = c(26, 33, 31, 19, 16, 11))
> x
Group Line.1 Line.2
1 (0, 25] 30 26
2 (25, 50] 31 33
3 (50, 100] 57 31
4 (100, 150] 42 19
5 (150, 250] 65 16
6 (250, 500] 84 11
> x=grouped.data(Group= c(0, 25, 50, 100, 150,250, 500),
Line.1 = c(30, 31, 57, 42, 65, 84),
Line.2 = c(26, 33, 31, 19, 16, 11),
right=F,row.names=LETTERS[1:6])
> x
Group Line.1 Line.2
A [0, 25) 30 26
B [25, 50) 31 33
C [50, 100) 57 31
D [100, 150) 42 19
E [150, 250) 65 16
F [250, 500) 84 11
提取子总体
> x[1,]
Group Line.1 Line.2
A [0, 25) 30 26
提取组频
> x[,2]
[1] 30 31 57 42 65 84
提取边界值。如果引用第一列你期待会出现什么结果呢?
> x[,1]
[1] 0 25 50 100 150 250 500
如同任何对数据框的操作,也可以对数据框中的数据进行修改。特别需要注意的是对第一列的修改,一定要明确指定分组区间的左右(或者中间)的边界值。如:
> x[1,1]=c(0,20)
> x
Group Line.1 Line.2
1 (0, 20] 30 26
2 (20, 50] 31 33
3 (50, 100] 57 31
4 (100, 150] 42 19
5 (150, 250] 65 16
6 (250, 500] 84 11
> x[c(3, 4), 1] x
Group Line.1 Line.2
1 (0, 20] 30 26
2 (20, 55] 31 33
3 (55, 110] 57 31
4 (110, 160] 42 19
5 (160, 250] 65 16
6 (250, 500] 84 11
如果只指定一个边界的话……
> x[1,1]=10
> x
Group Line.1 Line.2
1 (10, 10] 30 26
2 (10, 55] 31 33
3 (55, 110] 57 31
4 (110, 160] 42 19
5 (160, 250] 65 16
6 (250, 500] 84 11
2、分组统计
1)函数 mean() 计算分组均值。等价于
高阶矩的计算可以用函数 emm(), 见后文。
> x
Group Line.1 Line.2
A [0, 25) 30 26
B [25, 50) 31 33
C [50, 100) 57 31
D [100, 150) 42 19
E [150, 250) 65 16
F [250, 500) 84 11
> mean(x)
Line.1 Line.2
179.81392 99.90809
Line.1 的均值等价于:
> ((0+25)/2*30+(25+50)/2*31+(50+100)/2*57+(100+150)/2*42
(150+250)/2*65+(250+500)/2*84)/sum(x[,2])
[1] 179.8139
2)绘制直方图
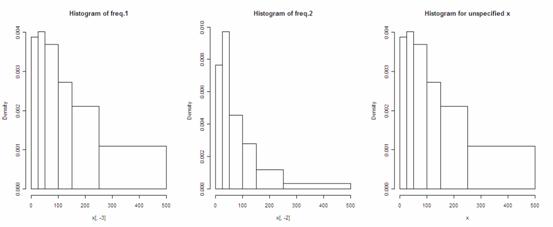
由于数据已经被划分好组别,因此 R 会应用数据框 x 的第一列作为组距的划分来绘制直方图,因此第一列一定要保留,这在绘制不等距直方图时是十分方便的。由于每次只能绘制一组频率,因此绘图时需要指定频率所在的列,如果不指定,默认绘制第一组频率(数据框的第二列)。
> layout(matrix(1:3,1,3))
> hist(x[,-3],main='Histogram of freq.1')
> hist(x[,-2],main='Histogram of freq.2')
> hist(x,main='Histogram for unspecified x')
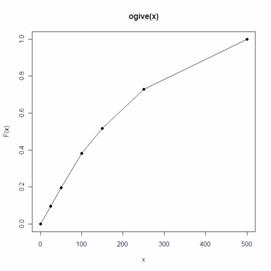
3)绘制累计频率图。如同对连续的随机变量可以绘制经验分布函数图一样,对于分组曲线也可以绘制 “拱形图”(ogive),也就是累计频率曲线,它通过将分组边界值所对应的累计频率用直线连接起来得到。累计频率曲线的公式如下:
函数 ogive()返回的是一个阶梯函数对象 (Step Function Class),也就是说返回的是一个函数,给定函数的横坐标,就可以返回相对应的频率,这点和 ecdf() 是相同的。我们可以通过 konts()返回阶梯函数对象的临界点,通过 plot()绘制阶梯函数。
> Fnt knots(Fnt) #返回临界点
[1] 0 25 50 100 150 250 500
> Fnt(knots(Fnt)) #返回临界点对应的累积频率值
[1] 0.00000000 0.09708738 0.19741100 0.38187702
0.51779935 0.72815534 1.00000000
> plot(Fnt)
3、计算经验矩
如果说均值函数 mean() 只能计算一阶矩,那么 emm() 函数则可以计算任意阶的经验原点矩。
首先引入 actuar 包中的两个数据集。其中 dental 是非分组数据,gdental 是分组数据。
> data(dental)
> dental
[1] 141 16 46 40 351 259 317 1511 107 567
> data(gdental)
> gdental
cj nj
1 (0, 25] 30
2 ( 25, 50] 31
3 ( 50, 100] 57
4 (100, 150] 42
5 (150, 250] 65
6 (250, 500] 84
7 (500, 1000] 45
8 (1000, 1500] 10
9 (1500, 2500] 11
10 (2500, 4000] 3
emm() 函数可以计算任意阶经验原点矩,其使用方法是这样的: emm(x,order=1)。其中,x 可以是数据向量或者是矩阵,如果是分组数据,x 也可以是由 grouped.data() 生成的数据框。order 是阶数,可以赋值给它一个向量,这样就能一次性计算多个原点矩。
当为非分组数据时,计算的公式为:
当为分组数据时,计算的公式为:
> emm(dental,2)
[1] 293068.3
> emm(gdental,1:3)
[1] 3.533399e+02 3.576802e+05 6.586332e+08
elev() 函数可以计算经验有限期望值(limited expected value)。使用方法是 elev(x):x 可以是非分组数据,也可以是分组数据,如果是分组数据,默认以第一组频率为计算对象。
对于非分组数据,有限期望值的公式为:
对于分组数据,有限期望公式比较复杂,在此略去。
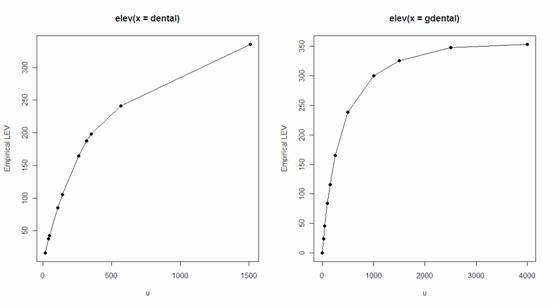
注意到,有限期望值是上限值 u 的函数。
> lev=elev(dental)
> lev(knots(lev))
[1] 16.0 37.6 42.4 85.1 105.5 164.5 187.7 197.9 241.1 335.5
> lev2=elev(gdental)
> par(mfrow=c(1,2))
> plot(lev,type='o',pch=19)
> plot(lev2,type='o',pch=19)
4、分布拟合
在 R 中,MASS 包中的 fitdistr() 函数可以用极大似然估计,对数据进行分布拟合。在 actuar() 包中,mde() 函数则提供了三种基于距离最小化的估计方法(minium distance estimates)。
1) Cramér-von Mises 方法(CvM)最小化理论分布函数和经验分布函数(对于分组数据是 ogive)的距离。
未分组数据:
分组数据:
在这里,是理论分布函数,是其参数;是经验分布函数 ecdf;是累积频率函数 ogive;是权重,默认都取 1。
2)修正卡方法仅应用于分组数据,通过最小化各组期望频数与实际观测频数的平方误差得到。
其中,,默认情况下为。
3)LAS 法(layer average severity)也仅应用于分组数据。通过最小化各组内的理论和经验有限期望函数的平方误差得到。
其中,,是理论分布的有限期望函数,而是经验分布的有限期望函数。默认情况下为。
函数调用 optim() 函数做最优化,其语法为:
mde(x, fun, start, measure = c("CvM", "chi-square", "LAS"),
weights = NULL, ...)
其中:
- x 是分组的或未分组的数据。
- fun 是待拟合的分布,CvM 法和修正卡方法需要指定分布函数:dfoo。LAS 法需要指定理论有限期望函数。 Tips:R 中对于一些分布 foo 提供了 d,p,q,r 四种函数,分别是密度函数,分布函数,分布函数的反函数和生成该分部的随机数。在 actuar 包中,除了提供 R 中原先没有但在精算研究中很重要的分布(比如 pareto 分布)的上述函数外,还对一些连续分布(注意是连续分布!)额外提供了 m、lev 和 mgf 三种函数,m 是计算理论原点矩,lev 是计算有限期望函数,mgf 是计算矩母函数。对于经验数据,如上面介绍 actuar 包中提供了 emm() 和 lev() 来计算经验原点矩和经验有限期望函数。
- start 指定参数初始值。形式必须以列表的形式,形式可以见例子,有几个参数就要指定几个初始值。
- measure 是指定方法。weight 指定权重,否则采用默认权重。
- … 是其他参数,可以指定 optim() 函数中的参数,比如使用 L-BFGS-B 方法进行优化可以添加参数 method=“L-BFGS-B”。
我们可以对上面的 gdental 数据进行分布拟合。
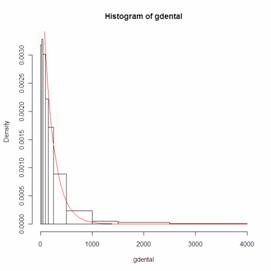
> mde(gdental,pexp,start=list(rate=1/200),measure="CvM")
rate
0.003551270
distance
0.002841739
Warning message:
In optim(x = c(0, 25, 50, 100, 150, 250, 500, 1000, 1500, 2500, :
one-diml optimization by Nelder-Mead is unreliable: use optimize
> hist(gdental)
> theta=1/200
> curve(theta*exp(1)^(-theta*x),from=0,to=4000,add=T,col='red')
 在此,我们感兴趣的是将基于距离的分布拟合方法与极大似然估计的参数估计效果进行以下对比。因此不妨做一个实验:
在此,我们感兴趣的是将基于距离的分布拟合方法与极大似然估计的参数估计效果进行以下对比。因此不妨做一个实验:
简单起见,先从单参数拟合问题开始,这是一个一维优化问题。
首先生成 50 组来自于 rate=1 的指数分布随机数,每组的个数都为 10。然后,对于每一组随机数,分别用基于距离的估计方法和极大似然估计进行参数估计,将 50 次模拟结果的均值和标准差记录下来。之后,将随机数的个数由 10 增加到 20,30…200,重复之前的过程。最终得到的结果如下图:
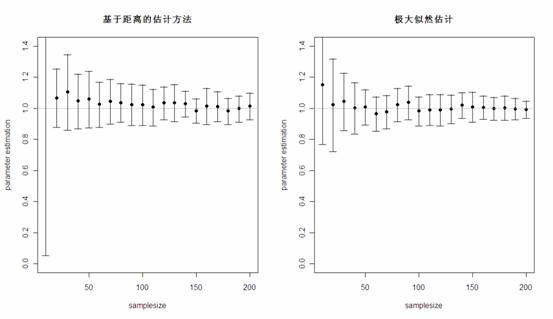
可以看出,在单参数估计中,尤其是在样本量较大时,两种方法估计的结果相差不大,而极大似然估计的方差要比基于距离的估计方差略小。那么,两种方法对于异常值的稳健性如何呢?在上面生成的所有组随机数中,剔除两个指数分布随机数,再混入两个来自 [200,300] 均匀分布的随机数,再重新对参数进行估计,结果很明显,基于距离的估计方法估计的结果很稳定,而极大似然估计的参数结果受异常值的影响很大!
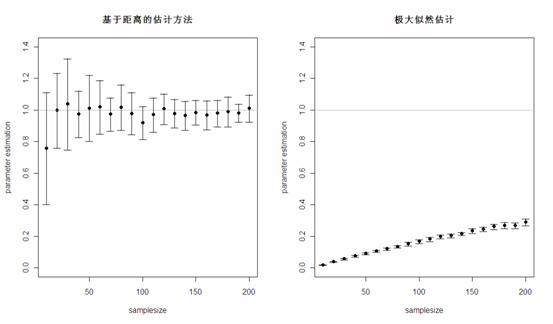
因此,对于经常存在异常值的损失数据,使用基于距离的分布拟合方法往往更加稳健。
对于两参数的估计,使用 mde() 函数经常会报错,通常的解决办法是估计参数的对数形式,然后再取指数还原,由于参数的对数形式可以取负值,这样程序虽然也会优化失败,但要比不取对数时的可能性要小很多。
比如:
> pgammalog=function(x,logshape,logscale)
{
pgamma(x,exp(logshape),exp(logscale))
}
>
> aa=rgamma(200,shape=3,scale=1)
> estlog=mde(aa,pgammalog,start=list(logshape=1.3,logscale=0.2),
measure='CvM',method='L-BFGS-B',lower=c(0.5,-0.5),
upper=c(1,5,0.5))$estimate
> exp(estlog)
logshape logscale
2.4873247 0.8404548
(未完待续)
敬告各位友媒,如需转载,请与统计之都小编联系(直接留言或发至邮箱:editor@cos.name),获准转载的请在显著位置注明作者和出处(转载自:统计之都),并在文章结尾处附上统计之都微信二维码。

发表 / 查看评论