学无止境。我曾以为我明白了如何在 Sweave 中使用缓存加快计算和图形,但后来发现我并没有真的理解,直到读了另外一些手册才明白,因此本文作为前文 “Sweave:打造一个可重复的统计研究流程” 之续集,向大家介绍一下如何在 Sweave 的计算和图形中使用缓存,以节省不必要的重复计算和作图,让那些涉及到密集型计算的用户不再对 Sweave 感到难堪。
如果你还没读前文,建议先从那里开始读,了解 Sweave 与 “可重复的统计研究” 的意义。简言之,Sweave 是一种从代码(R 代码和 LaTeX)一步生成报告的工具,我们可以把整个统计分析流程融入这个工具,让我们的报告具有可重复性。然而,就普通的 Sweave 而言,这样做的一个明显问题就是,所有计算和作图都被融入一个文档之后,每次运行这个文档都要重复所有的计算和作图,这在很多情况下纯粹是浪费时间;比如,我只想对新添加的部分内容运行计算,而文档中的旧内容希望保持不变。这都是很合理的需求,我们需要的实际上就是一种缓存机制,将不想重复计算的对象缓存起来,需要它的时候再从缓存库中直接调出来用。
Sweave 本身做不到缓存(或者很难做到),但由于 R 语言的扩展性以及一些疯子和天才的存在,我们可以通过 R 的一些附加包来完成缓存。这里的缓存有两种(不关心细节的读者可以略过):
一种是对 R 对象的缓存,比如数据、模型(拟合好的模型)和其它计算结果等,这个缓存容易理解,我们可以把它简单想象为把计算过程中的对象存入某些特殊的缓存库(文件),下次计算的时候先查看缓存库中是否存在我们需要的对象,如果存在,那么就直接加载进来,否则就重新计算;如(伪代码):
## 如果存在,就加载
if (file.exists('x.RData')) {
load('x.RData')
}
## 如果当前工作环境中不存在x,那么就重新创建它
if (!exists('x')) {
x = rnorm(100000)
}
R 对象的缓存可以通过 cacheSweave 包(作者 Roger D. Peng)实现,它真正采用的方法比上面的伪代码当然要高级(比如用代码的 MD5 值作数据库名等),不过用户可以不必关心这其中的细节。这种 “当需要时才加载” 的方式在术语上叫“延迟加载”,即 Lazy Load,这在 R 里面也很常见,比如很多 R 包的数据都是采用延迟加载的方式(加载包的时候并不立刻加载数据,而是用data(name)在需要的时候加载)。
另一种是图形的缓存,这是一个不可思议的魔法。cacheSweave 的帮助文档和 vignette 中特别提到了它只能缓存 R 对象,无法缓存图形和其它附属输出,而开源世界的魅力就是你总能找到一些奇妙的解决方案。R 包 pgfSweave 借力于 pgf 实现了图形的缓存。pgfSweave 包的两位作者 Cameron Bracken 和 Charlie Sharpsteen 都是水文学相关专业出身,却在 R 的世界里做了这些奇妙的工作,让我觉得有点意外,这是题外话。pgf 是 LaTeX 世界的又一项重大发明,它提供了一套全新的绘图方式(语言),而且它的图形可以通过 LaTeX 直接生成 PDF 输出(这是 pgfSweave 能实现缓存的关键)。关于 pgf,我们可以翻一翻它 726 页的手册,如果你能坚持看上 10 分钟,感叹超过 50 次,那么你一定是一位超级排版爱好者。它的图形质量之高、输出之漂亮,真的是让人(至少让我)叹为观止。同样,这里我也不详细介绍细节。pgf 图形的 “缓存” 是通过“外置化”(externalization)来实现的,简言之,pgf 图形有一种输出形式如下:
\beginpgfgraphicnamed{graph-output-1}
\input{graph-output-1.tikz}
\endpgfgraphicnamed
如果 LaTeX 在运行过程中遇到这样的代码段,那么它会把 tikz 图形(tikz 是高层实现,pgf 是基础设施)先编译为 PDF 图形,等下次重复运行 LaTeX 的时候,这段代码就不必重新运行了,LaTeX 会跳过它直接引入 PDF 图形。这样就省去了编译 tikz 图形的时间,同时也能得到高质量的图形输出。
pgfSweave 从 R 的层面上可以输出这样的代码段,并生成一个 shell 脚本来编译图形为 PDF;而 pgfSweave 也会尝试根据 R 代码的 MD5 来判断一段画图的代码是否需要重复运行——如果 R 代码没有变化,那么图形就不必重制。这是自然而然的 “缓存”。对了,pgfSweave 对 Sweave 的图形输出作了扩展,新增了 tikz 输出,这是通过另一个 R 包 tikzDevice 实现的(同样两个作者),这个包可以将 R 图形录制为 tikz 绘图代码。pgfSweave 依赖于 cacheSweave 包,把它缓存 R 对象的机制也引入进来,所以我们可以不必管 cacheSweave,把精力放在 pgfSweave 上就可以了。
介绍完血腥的细节之后,我们就可以坐享高科技的便利了。下面我以一个统计计算中的经典算法 “Gibbs 抽样” 为例来展示 pgfSweave 在密集型计算中的缓存功能。
Gibbs 抽样的最终目的是从一个多维分布中生成随机数,而已知的是所有的条件分布、、……、,并且假设我们可以很方便从这些条件分布中抽样。剩下的事情就很简单了:任意给定初始值,括号中的数字表示迭代次数,接下来依次迭代,随机生成、、……、(迭代次数),也就是,根据上一次的迭代结果并已知条件分布的情况下,从条件分布中生成下一次的随机数(这个算法很简单,你什么时候看明白上标下标了就明白了)。这是个串行的过程,所以无法避免循环。
接下来的计算没有那么复杂,我们仅仅用一个二维正态分布为例。当我们知道一个二维正态分布的分布函数时,我们也知道它的两个边际分布都是一维正态分布,而且分布的表达式也很明确,后文我会详细提到,读者也可以参考维基百科页面。生成一维正态分布的随机数对我们来说当然是小菜一碟——直接用rnorm()就可以了。这样,我们只需要交替从和生成随机数,最终我们就能得到服从二维联合分布的随机数(对)。假设我们要从下面的二维正态分布生成随机数:
详细过程和结果参见下面这份 PDF 文档(点击下载):A Simple Demo on Caching R Objects and Graphics with pgfSweave (PDF)
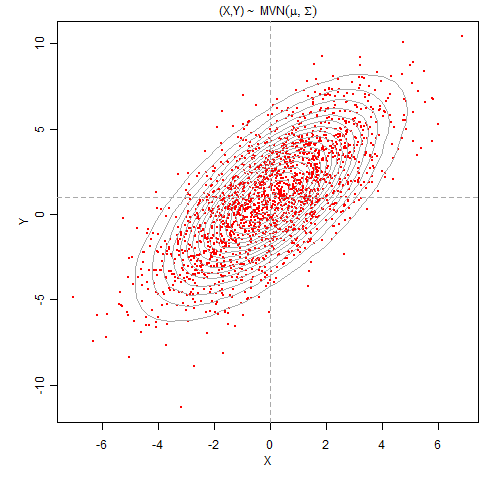
我们生成了 50 万行随机数,并画了 X 与 Y 的散点图。由于我们设定了相关系数为 0.7,所以图中自然而然显现出正相关;而等高线也体现出多维正态分布的 “椭球形” 特征。均值在 (0, 1) 附近,都和理论分布吻合。所以这个 Gibbs 抽样还不太糟糕。
生成上面的 PDF 文档和图形的 LyX/Sweave 源文档在这里 :A Simple Demo on Caching R Objects and Graphics with pgfSweave (LyX)
如果你已经按照我前面的文章配置好你的工具(即使当时配置过,现在也需要重新配置,因为我最近作了重大修改),这个文档应该可以让你重新生成我的结果。文档中有两处关键选项:
cache=TRUE使得文档中的 R 对象可以被缓存;external=TRUE使得图形可以被缓存;
第一次运行文档时,也许需要等待一分钟左右的时间,因为 R 需要长时间的 Gibbs 抽样计算,并编译生成的图形为 PDF,但如果下一次再运行这个文档,则速度会快很多,因为不需要再计算任何东西,只需从缓存加载就可以了。我们前一次的抽样结果已经在缓存库中了。
本文至此可以结束,但真正想享用这个结果的读者可能还要继续看几个问题:
-
pgfSweave 对图形的缓存经常有点过度,即使你改动了代码,缓存仍然不会被替换,这种情况下你可以把生成的 tikz 和 pdf 图形删掉;
-
中文问题:tikzDevice 包好像还没有完全解决中文问题,作者正在尝试我提供的中文图形,也许在未来不久的新版本中会有完全的中文支持,但目前实际上我已经在我的自动配置脚本中解决了这个问题。我们只需要保证我们的中文 LyX 文档用 UTF-8 编码就可以了——在文档选项中使用 CTeX 类(以及 UTF8 选项),并设置语言为中文、编码为 Unicode (XeLaTeX) (utf8)。这种设置至少我在 Windows 和 MikTeX 下可以成功编译中文 Sweave 文档。目前高亮代码功能在中文文档中还不能用,但我已经向相关作者发了补丁,等 CRAN 管理员回来发布新版 parser 包之后这个问题也会解决。所以,中文用户也不必担心,一切都(将)可以使用。
-
依旧是样式问题:细心的读者也许能发现上面的 PDF 文档中的图形和这里网页中的图形略有区别,PDF 文档中图形的字体和正文字体是一致的,这也是 pgf 的优势,前文第 5 节曾提到过。
-
如果使用缓存,那么代码段中的对象都无法打印出来,即使用
print(dat)也无法打印dat,这是因为缓存的代码段只管是否加载对象,而无法执行进一步的操作(包括打印),对于这种情况,我们应该设计好我们的 Sweave 文档结构,让某些代码段作计算(并缓存),某些代码段作输出(不要缓存)。
这两篇文章都有点长,但最终的操作都极其简单。如果能理解这套工具,我想无论是写作业还是写报告,都将事半功倍(比如我就一直用它写作业)。
祝大家在新的一年能写出漂亮、利索的统计文档,告别复制粘贴的体力劳动。
关于作者
谢益辉中国人民大学统计硕士,爱荷华州立大学统计学博士,R 包 knitr 的主要作者。现为 RStudio 软件工程师,曾负责 Shiny 包相关开发工作,后转入 R Markdown 相关扩展包的开发,包括 bookdown 和 blogdown。对统计计算、可视化、以及各类网页相关技术感兴趣,有志于对技术写作工具做减法工作,坚信人类浪费了太多时间在期刊论文、学位论文、书籍的排版上。平时主要活跃在 Github 上。个人主页在 https://yihui.org,思想偏激,流水账、意识流甚多,小人之心甚重,慎入。 |  |
敬告各位友媒,如需转载,请与统计之都小编联系(直接留言或发至邮箱:editor@cos.name),获准转载的请在显著位置注明作者和出处(转载自:统计之都),并在文章结尾处附上统计之都微信二维码。

发表 / 查看评论