首页
关于
论坛
R会
投稿
搜索
机器学习
最近更新于2023-02-25
3 / 3
统计应用
LDA-math-LDA 文本建模
靳志辉
/
2013-03-07
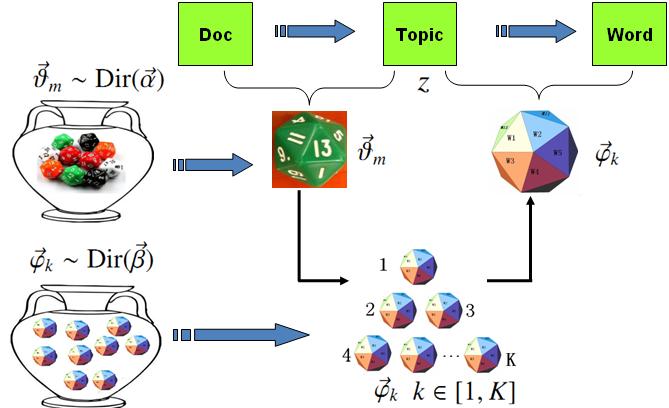
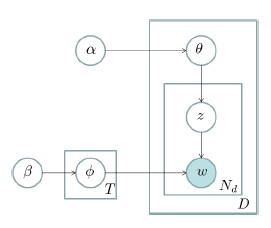
对于上述的 PLSA 模型,贝叶斯学派显然是有意见的,doc-topic 骰子$\overrightarrow{\theta}_m$和 topic-word 骰子$\overrightarrow{\varphi}_k$都是模型中的参数,参数都是随机变量,怎么能没有先验分布呢?于是,类似于对 Unigram Model 的贝叶斯改造, 我们也可以如下在两个骰子参数前加上先验分布从而把 PLSA 对应……
统计应用
LDA-math-文本建模
靳志辉
/
2013-03-07
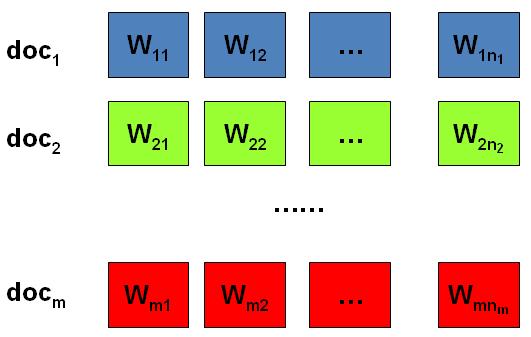
我们日常生活中总是产生大量的文本,如果每一个文本存储为一篇文档,那每篇文档从人的观察来说就是有序的词的序列$d=(w_1, w_2, \cdots, w_n)$。 包含$M$篇文档的语料库 统计文本建模的目的就是追问这些观察到语料库中的的词序列是如何生成的。统计学被人们描述为猜测上帝的游戏,人类产生的所有的语料文本我们都可以看成是一个伟大的上帝在天堂中抛掷骰子生成的,我们观察到的只是上帝玩这个游戏……
机器学习
十八般武艺,谁主天下?
陈丽云
/
2013-02-05
十八般武艺各有神通之处,所谓“一弓、二弩、三枪、四刀、五剑、六矛、七盾、八斧、九钺、十戟、十一鞭、十二锏、十三挝、十四殳、十五叉、十六耙、十七绵绳套索、十八白打”,这让一个江湖新手一上来就学全十八般武艺,还真是有点为难人家呢。这在古代,天下可都是一群架一群架扎扎实实打出来的。指挥者可以运筹帷幄决胜于千里之外,但是真要上阵的小兵们可就惨多了——谁若是稍有走神,怕是小命就危在旦夕了。还有那血雨腥风却始……
推荐文章
统计学习那些事
杨灿
/
2011-12-14
编辑部按:本文转载Yang Can主页中的文章,稍有修改,原文链接请点击此处。 作者简介:杨灿,香港科技大学电子与计算机工程系。 […] 主页:https://sites.google.com/site/eeyangc/ […] 在港科大拿到PhD,做的是Bioinformatics方面的东西。Bioinformatics这个领域很乱,从业者水平参差不齐,但随着相关技……
统计应用
分类器评价、混淆矩阵与ROC曲线
阿稳
/
2011-09-16
本文转载自阿稳的博客,原文链接请点击此处。本文主要介绍了数据挖掘中分类器的评价指标,以及混淆矩阵、ROC曲线等内容。 作者简介:阿稳,豆瓣,算法工程师。感兴趣的领域:推荐系统,数据挖掘,算法架构及实现的可扩展性,R环境编程。博客http://www.wentrue.net/blog/。 假定你基于贝叶斯理论、神经网络或其他技术建立了自己的分类器。你如何得知自己是否干了一项漂亮的工作呢?你如何得知是……
统计应用
统计词话(一)
邱怡轩
/
2011-03-04
不知道这个标题是否有足够的吸引力把你骗进来。如果你认为统计是一个到处充满了期望方差分布回归随机多元和概率的东西,那么……你可能是对的,不过本文想要告诉你的是,你其实还可以用统计来做一些你关心的事情,比如现在,我们既谈风月,也谈统计。:D 相信大家对宋词都不会陌生。无论你是否喜欢,总还是可以吟诵出几句名篇来的。如果你经常找一些宋词来读的话,你可能会发现一个有趣的现象,那就是有些词语或意象似乎特别受……
机器学习
LDA主题模型简介
范建宁
/
2010-10-08
上个学期到现在陆陆续续研究了一下主题模型(topic model)这个东东。何谓“主题”呢?望文生义就知道是什么意思了,就是诸如一篇文章、一段话、一个句子所表达的中心思想。不过从统计模型的角度来说, 我们是用一个特定的词频分布来刻画主题的,并认为一篇文章、一段话、一个句子是从一个概率模型中生成的。 D. M. Blei在2003年(准确地说应该是2002年)提出的LDA(Latent……
机器学习
COS竞赛:英文站点会员类型的识别
谢益辉
/
2009-03-17
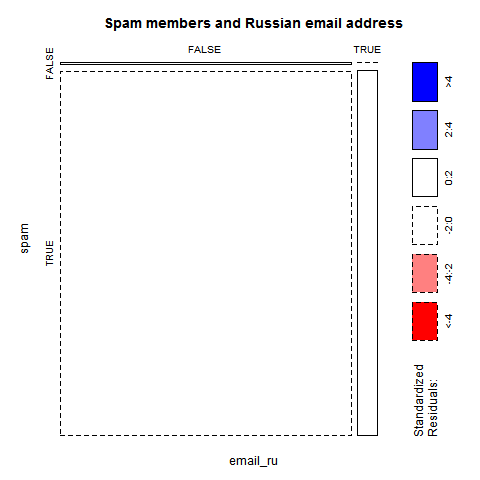
大家好,为了促进大家对统计之都的了解,并锻炼各位会员的统计应用能力,即日起我们推出“COS竞赛”系列活动。第一期活动的主要任务是分析统计之都英文网站(https://cos.name/en/)的会员数据,从中找出识别正规会员和机器人(垃圾、广告、自动注册)会员的规律。 […] 原始数据来自phpBB论坛的phpbb_users数据库,其中包含用户id、用户名、是否激活、Email、发……
机器学习
统计学博文导读:火箭队比赛与分类树、神经网络与降维
谢益辉
/
2009-03-15
即日起,统计之都网站成立“统计学博文导读”栏目,归属于“网站导读”栏目。我们号召广大读者和作者将喜爱的统计学博客文章推荐给我们,以方便更多读者在这个信息爆炸的时代能够快速阅读到优秀的文章;本文是统计之都“统计学博文导读”第一篇,权当示范本栏目的作用。这次我们重点推荐两篇博文,分别来自于刘思喆和左辰,向大家展示统计学理论的生活和思维魅力: […] 2009年3月5日,刘思喆发表了“从数……
机器学习
分类模型的性能评估——以SAS Logistic回归为例(3): Lift和Gain
胡江堂
/
2009-02-18
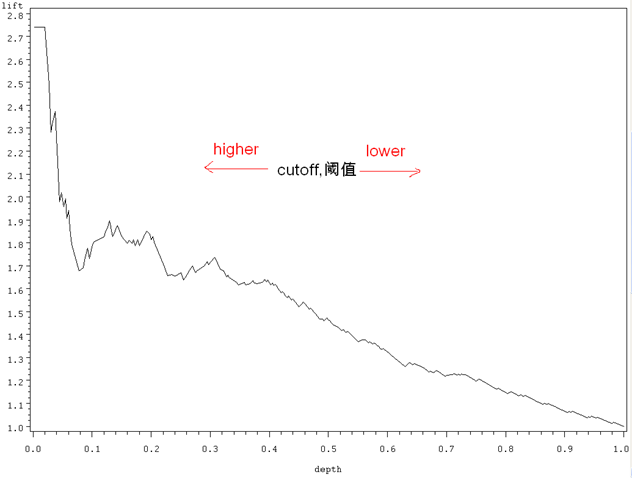
书接前文。跟ROC类似,Lift(提升)和Gain(增益)也一样能简单地从以前的Confusion Matrix以及Sensitivity、Specificity等信息中推导而来,也有跟一个baseline model的比较,然后也是很容易画出来,很容易解释。以下先修知识,包括所需的数据集: […] 说,混淆矩阵(Confusion Matrix)是我们永远值得信赖的朋友:……
机器学习
分类模型的性能评估——以SAS Logistic回归为例(2): ROC和AUC
胡江堂
/
2008-12-31
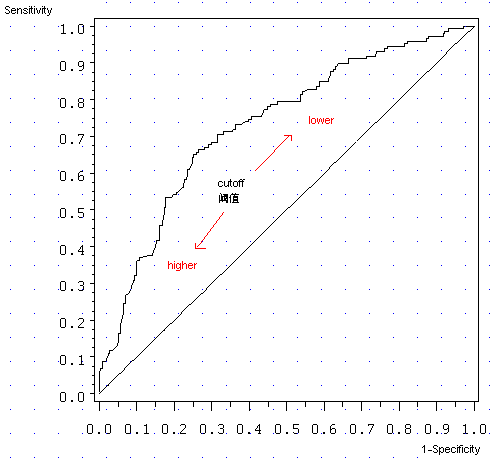
上回我们提到,ROC曲线就是不同的阈值下,以下两个变量的组合(如果对Sensitivity和Specificity两个术语没有概念,不妨返回,《分类模型的性能评估——以SAS Logistic回归为例(1): 混淆矩阵》,强烈建议读者对着看): […] Sensitivity(覆盖率,True Positive Rate) 1-Specificity (Specificity, 负例……
机器学习
分类模型的性能评估——以SAS Logistic回归为例(1): 混淆矩阵
胡江堂
/
2008-12-25
跑完分类模型(Logistic回归、决策树、神经网络等),我们经常面对一大堆模型评估的报表和指标,如Confusion Matrix、ROC、Lift、Gini、K-S之类(这个单子可以列很长),往往让很多在业务中需要解释它们的朋友头大:“这个模型的Lift是4,表明模型运作良好。——啊,怎么还要解释ROC,ROC如何如何,表明模型表现良好……”如果不明白这些评估指标的背后的直觉,就很可能陷入这样……
««
«
1
2
3
»
»»